
HTML tables are most often used to represent information on a web page. Software testers can use Selenium Webdriver for accessing tables and reading data at runtime. In this post, we’ll tell you multiple ways to handle HTML tables in Webdriver. We will cover static tables, nested tables, and dynamic tables so that you can understand the concept thoroughly.
To help you out, we’ve added code examples for each method given here to handle the web tables. So that you can start practicing them even while you are reading this post. But apart from the Selenium Webdriver commands, you must also know how to use XPath to locate an element in the web table. Here is a list of quick links to run you through the different sections of this post.
So let’s begin to learn the best ways to handle HTML tables.
Handle HTML Tables in Selenium
Generally, there is an <id> or <name> attribute associated with all the HTML fields. That becomes a unique identifier for locating the element on the web page.
But it isn’t the way that you can apply to a table for accessing its cells. Not even you can use methods that you normally do with Selenium like <By.id()>, <By.name()>, and <By.cssSelector()> to find a web element. Rather you should go with the <XPath> locator and <By.xpath()> method for handling HTML tables and cells.
How to Get XPath for a Table Cell
You need to learn about XPath. It’ll help you in handling HTML tables and accessing web elements. First of all, consider the following HTML code.
<html>
<head>
<title>Sample Table</title>
</head>
<body>
<table border="1">
<tbody>
<tr>
<td>cell one</td>
<td>cell two</td>
</tr>
<tr>
<td>cell three</td>
<td>cell four</td>
</tr>
</tbody>
</table>
</body>
</html>We will use the XPath locator to get the inner text of a cell containing the text “cell four”.

Let’s find out the XPath for cell number four.
Step 1 – Set Parent Element
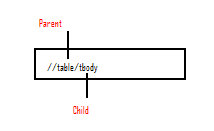
XPath locators in WebDriver always start with a double forward slash “//” followed by the parent element tag. Since we are dealing with tables, the parent element should always be the <table> tag. The first portion of our XPath locator should start with the “//table”.
Step 2 – Add Child Elements
The element immediately under <table> tag is <tbody> so we can say that <tbody> is the “child” of <table>. And also, <table> is the “parent” of <tbody>.

While forming an XPath, you need to place all child elements to the right of their parent element. And please remember to use a forward slash to chain the elements.
Step 3 – Add Predicate Index
The <tbody> element contains two <tr> tags. We can now say that these two <tr> tags are “children” of <tbody>. The other way round <tbody> is the parent of both the <tr> elements.
The two <tr> elements having the same parent <tbody> can be called siblings. Thus Siblings refer to child elements having the same parent.
To access the <td> (the one with the text “cell four”), we have to first go to the second <tr> and not the first. If we simply write "//table/tbody/tr", then we will be accessing the first <tr> tag.
So, how to access the second <tr> then? The answer to this is to use Predicates.
Predicates represent the index of HTML child elements that are Siblings and are enclosed in a pair of square brackets “[ ]”. This index clearly distinguishes a child element from its siblings. Since the <tr> we need to access is the second one, so we’ll use “[2]” as the predicate.
//table/tbody/tr[2]If you don’t use any predicate, then XPath will always point to the first sibling. Hence, both of them should access the first <tr>.
//table/tbody/trThe above code will automatically locate the first <tr> as no predicate is specified. But the below line will select the same row because the predicate value is “1”.
//table/tbody/tr[1]Step 4 – Add Child Elements
In the previous steps, we’d reached the second row. Next, we’ve to move to the second <td> element. Applying the same technique that we have used in steps 2 and 3, the XPath will come out to be the one shown below.
//table/tbody/tr[2]/td[2]Using the above XPath locator, you can access the cell and obtain its inner text using the code below.
public static void main(String[] args) {
String baseUrl = “file: ///D:/Technology/Selenium cases/Table.html”;
Webdriver driver = new FirefoxDriver();
driver.get(baseUrl);
String cellText = driver.findElement(By.xpath(“ //table/tbody/tr[2]/td[2]”)).getText();
System.out.println(“Text in Cell four is: ”+cellText); driver.quit();
}Output:
Text in Cell four is: cell four.Handle Nested Tables in Selenium
Nested tables are HTML tables defined within a table. For handling HTML tables you can try the same way as given above. Consider the below code.
<html>
<head>
<title>Sample Table</title>
</head>
<body>
<table border="1">
<tbody>
<tr>
<td>NAME</td>
<td>ADDRESS</td>
</tr>
<tr>
<td>ALICE</td>
<td>
<!-- inner table -->
<table border="1">
<tbody>
<tr>
<td>Elephanta Road</td>
<td>Delhi</td>
</tr>
<tr>
<td>Electronic City</td>
<td>Noida</td>
</tr>
</tbody>
</table>
</td>
</tr>
</tbody>
</table>
</body>
</html>To access the cell with the text “Electronic City” using the “//parent/child” and predicate concepts that we learned in the previous section, we get the following XPath.
//table/tbody/tr[2]/td[2]/table/tbody/tr/td[2]
V V
Outer table Inner tableBelow is the complete Selenium WebDriver code for handling HTML tables and the text of the cell that we discussed.
public static void main(String[] args) {
String baseUrl = “file: ///D:/Technology/Selenium cases/ Nested_Table.html”;
Webdriver driver = new FirefoxDriver();
driver.get(baseUrl);
String cellText = driver.findElement(By.xpath(“ //table/tbody/tr[2]/td[2]/table/tbody/tr/td[2]”)).getText();
System.out.println(“Text in Cell five is: ”+cellText); driver.quit();
}Output:
Text in Cell is: Electronic city.Handle Dynamic Tables in Selenium
Handling data from an HTML table becomes difficult in the following cases.
1- When table rows and columns change after loading the page.
2- When a table has some rows with more cells and some rows with fewer cells, then you need to refactor the code to handle this.

Sample HTML Table
<html>
<head>
<title>Sample Table</title>
</head>
<body>
<table border="1">
<tbody>
<tr>
<td>A</td>
<td>B</td>
<td>C</td>
<td>D</td>
</tr>
<tr>
<td>E</td>
<td>F</td>
<td>G</td>
</tr>
<tr>
<td>H</td>
<td>I</td>
<td>J</td>
<td>K</td>
</tr>
<tr>
<td>L</td>
<td>M</td>
</tr>
<tr>
<td>N</td>
<td>O</td>
<td>P</td>
</tr>
</tbody>
</table>
</body>
</html>The above HTML code forms a dynamic table with rows having inconsistent no. of cells. The logic to read data from such a table is to first move to a row of that table, then count the number of cells in that row, and based on the number of cells retrieve data from a particular cell.
Selenium Code for Handling Tables
import java.util.List;
import java.util.concurrent.TimeUnit;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import org.openqa.selenium.firefox.FirefoxDriver;
public class dynamic_table {
public static void main(String[] args) throws InterruptedException {
WebDriver driver = new FirefoxDriver();
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);
String baseUrl = "file:///D:/Technology/Selenium%20cases/dynamic_table.html";
driver.get(baseUrl);
//To locate table.
WebElement mytable = driver.findElement(By.xpath("html/body/table/tbody"));
//To locate rows of table.
List < WebElement > rows_table = mytable.findElements(By.tagName("tr"));
//To calculate no of rows In table.
int rows_count = rows_table.size();
//Loop will execute for all the rows of the table
for (int row = 0; row < rows_count; row++) {
//To locate columns(cells) of that specific row.
List < WebElement > Columns_row = rows_table.get(row).findElements(By.tagName("td"));
//To calculate no of columns(cells) In that specific row.
int columns_count = Columns_row.size();
System.out.println("Number of cells In Row " + row + " are " + columns_count);
//Loop will execute till the last cell of that specific row.
for (int column = 0; column < columns_count; column++) {
//To retrieve text from the cells.
String celltext = Columns_row.get(column).getText();
System.out.println("Cell Value Of row number " + row + " and column number " + column + " Is " + celltext);
}
}
}
}Before You Leave
We suggest you try to practice the HTML and Java code given above. This is how you can get the maximum benefit from this tutorial. If you face any problems while handling the HTML tables in the Selenium web driver project, then do write to us. We’ll try to get back at the earliest.
If you want us to write on a topic of your choice, then also contact us. We’ll surely add it to our interest list and deliver a post as soon as we can.
Before you leave, render your support for us to continue. If you like our tutorials, share this post on social media like Facebook/Twitter.
Happy testing,
TeamBeamers.







