
Apache Spark is a very popular data processing and analytics framework. It brings the ability to process and analyze large data with ease. In this short tutorial, we’ll know about it more and mainly about the Apache Spark architecture.
Apache Spark – Introduction
Apache Spark is a free, powerful tool for handling lots of data all at once. Think of it like a super-smart manager that organizes tasks across many computers, making them work together efficiently. Unlike older methods like MapReduce, Spark is more flexible and works smarter, making it a top choice for dealing with big data. It’s a master tool for solving your data tasks and executing them faster and more efficiently. Spark simplifies the complex world of data processing, making it accessible for everyone who wants to make the most out of their large-scale data.
Main Purpose
The main purpose of Apache Spark is to provide a highly responsive and open cluster computing framework for big data processing. It aims to make distributed data processing accessible and efficient, offering a rich set of APIs for programming in all modern languages. Spark supports a variety of workloads, including batch processing, interactive queries, streaming, machine learning, and graph processing.
Apache Spark Architecture
Apache Spark’s design revolves around an essential concept called Resilient Distributed Dataset (RDD). It’s a robust way to handle data that can tolerate faults and allows processing across multiple computers simultaneously.
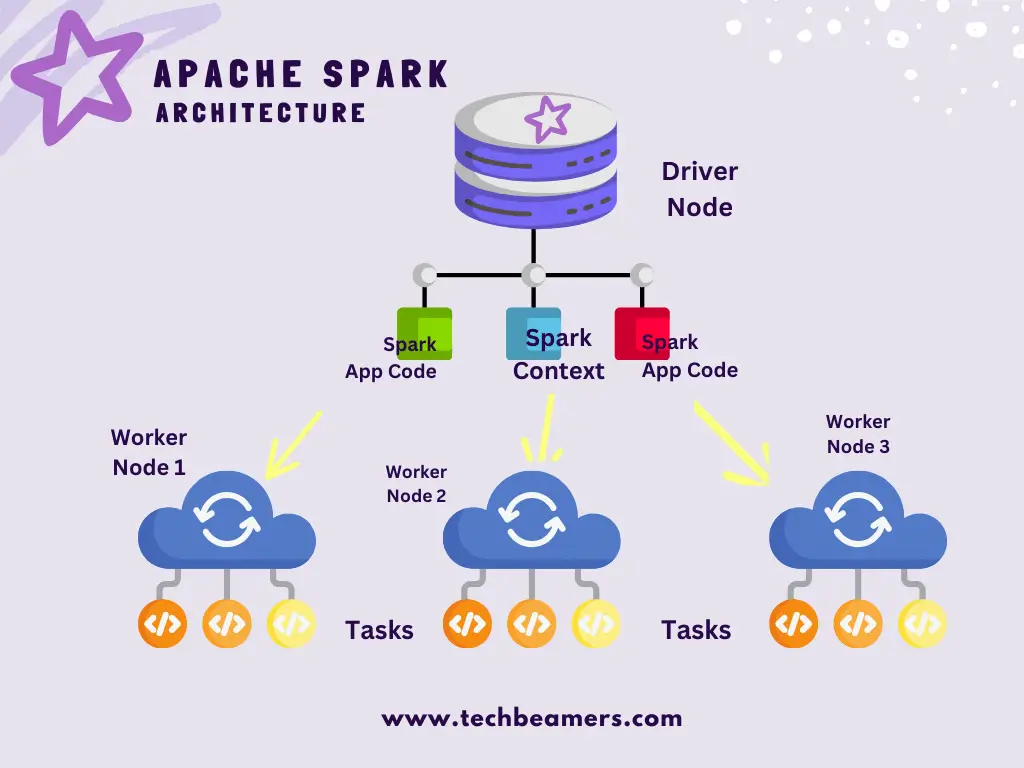
Here are the key components of the Spark architecture:
Driver Node
In Apache Spark, the Driver Node is like the main computer where the main program of a Spark application runs. It’s the one that starts and manages the whole Spark job. Instead of using fancy language, think of the Driver Node as the control center. It does important things like running the SparkContext and making sure the cluster of computers is handling tasks parallelly while ensuring the availability of resources. The Driver Node is the one that ultimately makes it possible for data processing to happen smoothly across the entire Spark cluster.
SparkContext
The second entity in the Apache Spark architecture is the SparkContext. It is like the brains behind the operation. It’s the component that kicks off and supervises the entire Spark application. Instead of being metaphorical, just see the SparkContext as the central control point. Its main job is to execute tasks and coordinate the distribution of these tasks across the cluster of computers. The SparkContext takes charge of managing how the application runs. It talks to the cluster manager to get the necessary resources. Furthermore, it ensures to get the data back after succesful processing from the entire Spark cluster.
Cluster Manager
In Apache Spark, the Cluster Manager is like the organizer of a big event. It’s the one that ensures everything runs smoothly in the Spark cluster. Without using fancy words, think of the Cluster Manager as the coordinator. Its main task is to manage resources, making sure each part of the Spark application gets what it needs. The Cluster Manager communicates with the Driver Node and assigns tasks to different computers in the cluster. Its role is vital in distributing the resources across, ensuring efficient and effective processing of data across the entire Spark cluster.
Note: We left out the Cluster Manager in the diagram to keep things simple and easy to understand, highlighting the main parts of Apache Spark.
Executor Nodes
- Machines in the cluster that execute tasks assigned by the SparkContext.
- Each executor runs multiple tasks in parallel, and they communicate with the driver node.
Resilient Distributed Dataset (RDD)
In Apache Spark, think of Resilient Distributed Dataset (RDD) as a super-smart way to split and process data across multiple computers at the same time. RDDs are like chunks of information that can handle errors and still keep going. They’re the backbone of Spark, making data processing speedy and reliable, even on big datasets.
Note: RDD in Apache Spark is like a smart way to work with lots of data at once, making things fast and reliable. We didn’t show it in the diagram to keep things simple, but it’s a crucial part of how Spark handles data.
Rich Interfaces
Spark makes things easier with its rich set of APIs supporting top languages like Java, Python, programming, Scala, and R. These APIs, like Spark SQL for structured data, MLlib for (ML) machine learning, GraphX for graphs, and Spark Streaming for real-time data, simplify complex tasks, making them more user-friendly.
Apache Spark FAQs
Here are some FAQs about Apache Spark to advance your understanding of this topic further.
What is the primary use of Apache Spark?
Apache Spark is a tool for handling lots of data at once. It can do various tasks like organizing data in batches, answering questions interactively, working on machine learning, handling graphs, and dealing with large real-time data.
How is Spark different from Hadoop?
Spark is a faster and more flexible tool compared to Hadoop. While Hadoop is mainly for processing data in batches, Spark can handle batches, answer questions interactively, and process data in real time, making it more versatile.
What makes up the Apache Spark architecture?
The Apache Spark architecture includes key parts such as the Driver Node, SparkContext, Worker Nodes, and Resilient Distributed Datasets (RDDs). These components collaborate to make data processing effective and distributed.
How does the Apache Spark architecture manage data processing?
In the Apache Spark architecture, the SparkContext takes care of data processing tasks by organizing and assigning them across the cluster. RDDs are essential in dividing tasks among Worker Nodes, ensuring efficient and reliable computation.
What is an RDD in Spark?
RDD (Resilient Distributed Dataset) is a way Spark organizes data. It’s like a reliable collection of information that can handle errors and is processed simultaneously across many computers in a group.
What is a Spark Application?
A Spark Application is a program created by a user to process data using Spark. It includes a main program called a driver and a bunch of tasks that run on a group of computers.
What is a Driver Node in Spark?
The Driver Node is like the main computer where the main program of a Spark application runs. It starts tasks, manages the SparkContext, and makes sure tasks are carried out across the group of computers.
What is SparkContext?
SparkContext is like the starting point for a Spark program. It connects to the group of computers, organizes tasks, and manages resources to make sure data is processed effectively.
How does Spark handle data processing tasks?
Spark uses RDDs, which are like chunks of data processed at the same time on many computers. The SparkContext distributes tasks to worker computers, and the results are combined to process data efficiently.
Does Spark support multiple programming languages?
Apache Spark has APIs for all major languages like Java and Python while supporting Scala, and R, making programming easier. They include Spark SQL for organizing structured data, MLlib for machine learning, GraphX for handling graphs, and Spark Streaming for working with data in real time.
These are just some common questions, and there’s a lot more to explore depending on your interests and what you want to do with Spark.
Conclusion
The typical flow involves a driver program running on the driver node, which creates a SparkContext. The SparkContext interacts with the cluster manager to allocate resources, and tasks are executed on the executor nodes. RDDs are used to represent and process distributed collections of data.
In summary, Apache Spark’s architecture is designed to handle distributed data processing efficiently, providing fault tolerance, scalability, and ease of use for a variety of big data workloads.







